A platform for scalable enterprise AI agents
AI agents are moving quickly from experimentation to practical enterprise use, but scaling them across an organization remains difficult. In this whitepaper, we share how Zenseact approached that challenge by building a platform that enables distributed ownership, allowing teams to create and manage their own agents, tools, and instructions within a shared framework.
13 min read

Summary
AI agents and agentic systems that combine large language models with tool execution to perform real work have flooded social media, tech blogs, and research papers over the last year, promising to increase productivity. The promise to enterprises is that these will accelerate development and cut costs while requiring less headcount. However, many organizations, even the AI native ones, struggle to scale their agentic platforms and systems, leaving only PoCs and narrow use-cases rather than an enterprise-wide changed way of working.
We built Zenseact AI Platform (ZAP), an AI agent framework on top of AWS Bedrock to test our hypothesis and our scaling strategy: that the right way to scale agents across an organization is not to centralize agents, but to distribute ownership and development. Rather than building a single master application, we built a platform and an execution framework in which teams define their own agents, own their own tools, and write their own domain instructions. This article describes the architecture, the engineering patterns behind it, and why we believe this model generalizes beyond our own organization.
Introduction
The shift from passive to agentic systems
The practical breakthrough in AI agents did not come from a single model release. It came from the maturation of three capabilities in combination:
- Reliable function-calling – LLM APIs that can emit structured tool invocations instead of just text, with consistent argument schemas and error handling.
- Instruction files as replicable behavior – The ability to encode domain expertise in structured markdown files that shape how an agent reasons, which tools it selects, and how it formats output.
- Deterministic tool loops – An execution pattern where the LLM proposes a tool call, the framework executes it, feeds the result back, and repeats up to a fixed iteration limit until the agent produces a final answer.
The result is a shift in what LLMs do. Rather than being passive systems that respond to a human prompt, they become reactive systems that can be scheduled, with multiple tool calls to decompose complex tasks, and can operate on live enterprise data. This is not artificial general intelligence; it is the application of well-understood software engineering patterns and event loops into a new kind of runtime. But the practical impact is large: workflows that previously required a human to query three systems and combine the results in a spreadsheet can now be expressed as an agent with three tools and a set of instructions.
The enterprise adoption gap
The open-source community has been building agentic systems for over a year. Enterprise adoption lags, not because the technology is immature, but because enterprise deployment requires answers to questions that hobby projects can ignore:
- How do you authenticate users and enforce role-based access to tools that can write to production systems?
- How do you manage prompt context when an agent has access to 20+ tools across 10 domains?
- How do you let a finance team and a CI/CD team each own their agent without creating a coordination bottleneck?
Initially we approached the adoption of AI Agents in our organization through using common open-source agentic frameworks and an external platform. This, however, did not scale. The open-source agentic framework did not provide enough supporting functions that led to non-generic implementations for each use case that were not possible to scale to new use cases. This meant that AI tool usage did not expand and measurable outcomes were lacking. Every new implementation required additional implementation of an agentic loop, knowledge bases etc.
Problem definition
The challenge
Enterprise organizations accumulate data across dozens of systems: ERP (SAP), issue trackers (JIRA), code review platforms (Gerrit), CI/CD pipelines (Zuul, GoCD), document stores (Confluence, SharePoint), observability platforms (Elasticsearch), and proprietary internal tools. Each system has its own API, its own query language, and its own access model.
The people who need answers from these systems are rarely the people who know how to write the API calls required to get those answers.
Why this is a problem
The traditional response is to build dashboards. But dashboards answer predetermined questions. When a manager asks, “Why is the cost variance for Department X higher this quarter, and is it related to the CI failure rate?”, no single dashboard answers that. The query requires combining SAP financial data with CI pipeline metrics, applying domain knowledge about what constitutes a meaningful variance.
An AI agent with access to both data sources, combined with domain knowledge, can answer this question in a single conversation turn.
Who is affected
Every team that consumes data from enterprise systems does not own or administer those systems. In our experience at Zenseact, this includes:
- Product development teams – querying JIRA, Gerrit, Zuul, and Elasticsearch for development workflow insights
- Finance and operations teams – querying SAP, SharePoint, and capacity planning tools for budget tracking and forecasting
- Support teams – querying service logs and pipeline monitoring tools for diagnostic information
Each of these groups has different tools and a different vocabulary. A single monolithic agent cannot serve all of them well.
Architecture – a platform, not an application
Design principle
Zenseact’s AI Platform architecture rests on a single design principle: the LLM decides which tool to call and how to format the output while tools do the actual work. The LLM should not be performing calculations, string manipulation, or data transformations in its response text. If it is, you are missing a tool.
This separation has a direct organizational consequence. If tools are self-contained Python modules with clear interfaces, and if domain instructions are text files, then creating a new agent becomes a configuration task and not a platform engineering project.
System overview
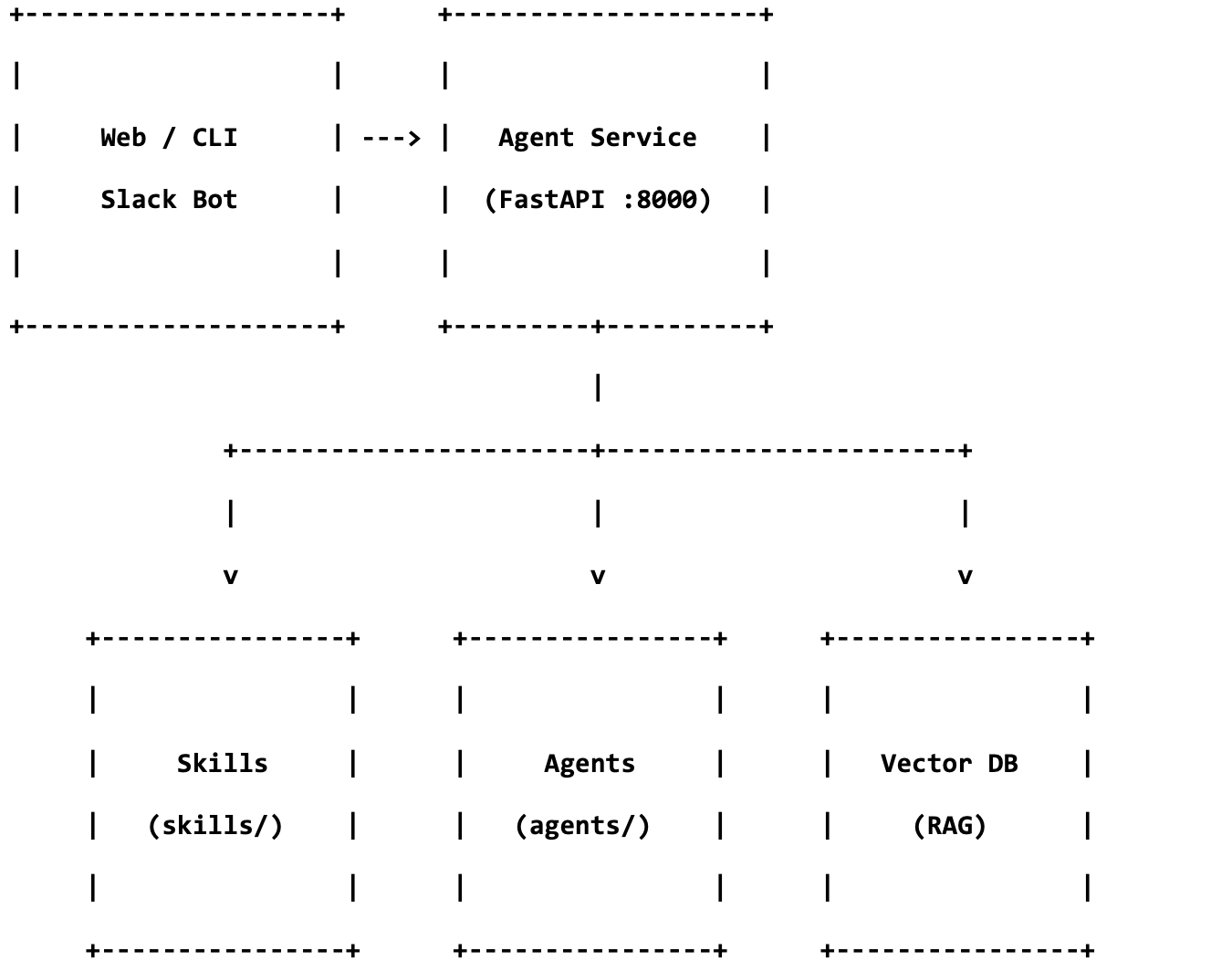
The Agent Service is the core runtime and handles authentication, session management, tool execution, and the LLM call loop. It does not contain any business logic.
Skills (skills/) are self-contained Python modules. Each skill exports tools via a factory function that returns callable tool definition. Skills are independent of the agent framework.
Agents (agents/) are configuration directories. Each contains a configuration of which model and skills, and domain expertise. An agent is defined by choosing which existing tools to compose and writing instructions for how the LLM should use them.
What this means for scaling
Creating a new agent does not require modifying the platform. It requires:
- A directory under agents/ with two files
- A config.yaml that lists which skill modules to load
- A SKILL.md that encodes the domain’s business rules, formatting preferences, and tool usage patterns
If the tools already exist, no Python code is needed at all. If new tools are needed, they are added as a self-contained skill module under skills/, the framework discovers and loads them at startup.
This is the mechanism that enables distributed ownership. The platform team maintains the framework, while domain teams maintain their agents and tools.
Patterns for Managing Skills in Agents
The hardest engineering problem in multi-tool agents is not to run tool executions, it is to decide which tools and which instructions to present to the LLM on each turn, given a limited context window.
The context window problem
An agent with access to 20 skill modules might have 150+ tools, each with its own parameter schema and usage instructions. Loading all this information and context into every LLM call is wasteful and degrades response quality.
Progressive skill disclosure
ZAP solves this with a two-level loading system:
Level 1, Frontmatter (always loaded). Every SKILL.md file has a YAML frontmatter block with a compact description of what the skill covers and which tools it provides. These summaries (typically 1.5–2KB total across all active skills) are always present in the system prompt. They tell the LLM what expertise is available without loading the full instructions.
Level 2, Body (loaded per-turn, on demand). The full markdown body, containing field maps, query recipes, workflow steps, and common mistakes, is injected only for skill packages that are semantically relevant to the current user query. After each turn, the previous injection is removed.
Relevance selection via TF-IDF
The selection algorithm is deliberately simple: TF-IDF cosine similarity between the user’s query and each skill’s frontmatter description, implemented without external ML dependencies. Packages above a similarity threshold are expanded; if nothing exceeds the threshold, all packages are expanded as a safe fallback.
This is fully dynamic without hardcoded tool name tables or keyword lists. Package discovery is driven entirely by scanning skills/*/SKILL.md frontmatter at startup. Adding a new skill requires only adding a SKILL.md file with a descriptive front-matter block.
Measured context savings: 67–98% for financial queries and 43–97% for engineering queries.
Self-tuning feedback loop

The system tracks skill disclosure misses, cases where the TF-IDF matcher selected the wrong packages or failed to match at all.
These are logged and surfaced in an admin monitoring dashboard, where they are used as input to an automated skill improvement pipeline.
Tool permissions and safety
Every tool call passes through a permission layer before execution. Permissions are configured per-tool and per-role in a YAML file:
- auto_approve – execute immediately (default for read-only tools)
- confirm – send the tool name and arguments to the user via SSE, wait for approval before executing
- deny – block execution entirely for that role
Tool arguments are validated for injection patterns before execution. Tool output is sanitized to remove potential prompt-injection markers embedded in data returned from external systems.
Model hot-swapping
Different tools may benefit from different models. An issue search tool might work best with a fast, cheap model; a complex financial analysis tool might need a larger model for accurate output interpretation. ZAP supports per-skill model overrides, any skill can declare a preferred model in its SKILL.md frontmatter, and the agent will switch models after executing that tool. The default model is restored afterward.
Implementation Considerations
Agent definition example

This agent has access to 7 skill modules (each contributing multiple tools), uses a specific model at low temperature for deterministic financial analysis, is accessible via web and API but not Slack, and can delegate queries to the product_development agent when a question spans both financial and engineering data.
Execution flow
For each user message, the agent:
- Selects relevant skill packages via TF-IDF and injects their instructions
- Detects domain-specific intents (e.g., JIRA query, executive summary request) and injects runtime guidance
- Retrieves RAG context (scoped by agent, skill, and user) and injects it
- Enters a tool loop (up to 25 iterations): LLM proposes tool calls → framework executes them → results are fed back → repeat until the LLM produces a final text response
- Finalizes: strips thinking tags, stores to memory, scores quality, detects skill disclosure misses
Multi-agent delegation
Agents can delegate to other agents. The financials agent, when asked about cross-function analysis, can invoke the product development agent to gather CI metrics and JIRA delivery data and synthesize both into a single executive scorecard. Delegation is permission-controlled (explicit allow-list in config) and depth-limited.
Example Workflow
User prompt: “Compare Q1 budget vs. actuals for the Data Platform and tell me if the CI pass rate is healthy.”
Agent: financials
- TF-IDF selects sap_odata and capacity_planning skills → injects their full instructions
- Leadership brief intent detected → injects Cross-function scorecard guidance
- Agent calls sap_get_breakdown(cost_center=”Data Platform”, year=2026) → gets financial data
- Agent calls sap_get_fte_totals(cost_center=”Data Platform”) → gets headcount data
- Agent delegates to product_development: “For Data Platform, provide CI pass rate, integrations/day, and gate duration for the last 30 days”
- Product development agent calls ci_premerge_stats(days=30) and ci_integration_frequency(days=30) → returns metrics
- Financials agent synthesizes all data into a single scorecard table with one-line verdict and drill-down suggestions
Total: 4 tool calls across 2 agents, in a single conversation turn.
Key takeaways
- Separate the platform from the agents. The framework handles authentication, session management, tool execution, and safety. Agents are configuration
- Progressive skill disclosure is essential at scale. Loading all instructions for all tools on every turn does not scale. A two-level system, compact summaries always present, full instructions loaded per-turn based on relevance, reduces context usage by 67–98% while maintaining accuracy.
- The LLM is an orchestrator, not a calculator. If the LLM is doing math, string manipulation, or data transformation in its response, you are missing a tool. Tools do the work; the LLM decides which tools to call and presents the results.
- Self-tuning closes the loop. Tracking skill disclosure misses, tool errors, and quality scores creates a feedback signal that can be used to improve instructions iteratively, without changing framework code.
- Distributed ownership scales. When creating an agent requires writing two text files and optionally a Python module, the barrier to entry is low enough that domain teams can own their agents. This eliminates the bottleneck of a central AI team that must understand every domain.
Conclusion
The architectural choice we made with ZAP is fundamentally about who owns the agents. A centralized approach, one team builds all agents for all domains, creates a coordination bottleneck that scales linearly with the number of use cases. A distributed approach, a shared platform with team-owned agents, scales with the organization.
This works because most code development is on the platform, while the domain-specific tuning is in configuration files that domain experts can write and iterate on.
We are not claiming that every employee will be building agents tomorrow. But we observe that the skills required to write clear instructions in a markdown file, defining tool parameters, and iterating based on test results are not exclusive to software engineers. They are closer to writing a good operating procedure than writing production code. As the tooling improves, we expect the gap between technical and non-technical agent creators to narrow, and the organizational model we describe here to become the default.
